Blame the Bot? Evaluating Racial Bias from Humans vs AI
 Image from Unsplash
Image from Unsplash
Summary
- This project explores how people evaluate racial bias differently when it originates from a human versus an AI system.
- It examines how bias explicitness (blatant vs. subtle) and perceiver race (White vs. non-White) influence emotional reactions and blame judgments.
- Key finding: People hold humans more accountable than AI for biased behavior, but shift blame toward AI trainers—reflecting awareness of human responsibility behind automation.
Challenge
-
Identifying relevant users: Recruited a racially diverse sample to evaluate bias from both human and AI agents across conditions.
-
Establishing user-centered relevance: The study responds to growing public concern about algorithmic bias and accountability, especially among historically marginalized groups.
-
Design realism: Creating vignettes that felt authentic for both human and AI perpetrators without evoking suspicion or confusion.
-
Balancing subtlety: Ensuring “subtle bias” scenarios were recognizable but not too obvious to participants.
-
Measuring moral attribution: Capturing nuanced blame at multiple levels (perpetrator, trainer, society) without inflating survey length.
Solutions to the challenge
- Developed paired Human vs. AI vignettes with identical wording except for agent identity (“Tod Smith” vs. “TodSMith”).
- Used pretesting and comprehension checks to validate clarity and emotional impact.
- Applied linear mixed-effects models (REML) to account for individual variability in emotional and moral responses.
Goal
To understand how people attribute intentionality, accountability, and moral blame when encountering bias from human versus AI agents—and how these judgments differ across racial groups and levels of bias explicitness.
Why it matters
- Offers insight into how algorithmic bias is morally interpreted by diverse audiences.
- Informs AI governance and communication strategies, highlighting public intuitions about fairness and accountability.
- Contributes to the broader dialogue on ethical AI development and social trust in automation.
Research Process
Stage 1: Study design
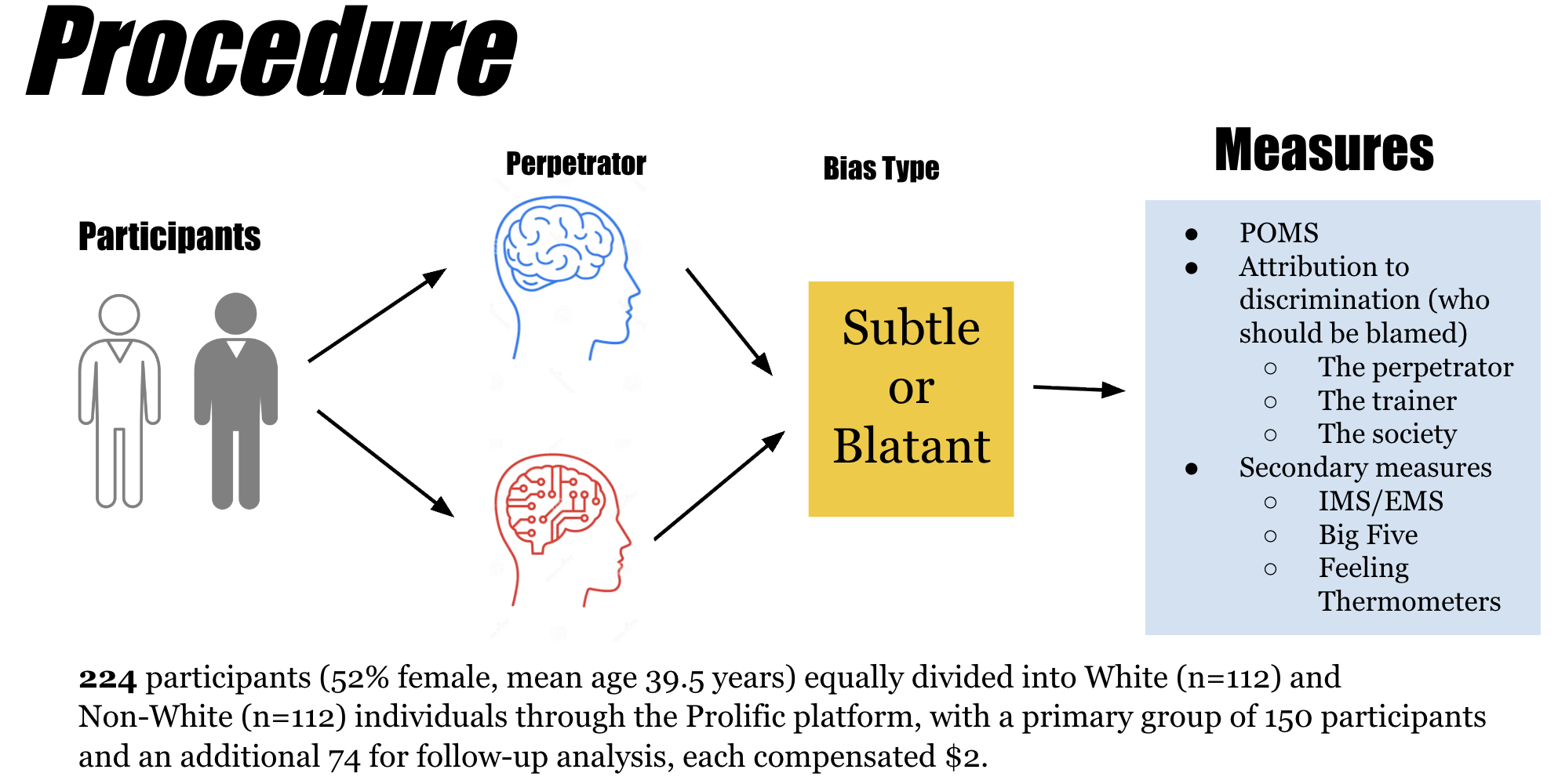
- Participants: 224 individuals (52% female; 112 White, 112 non-White) recruited via Prolific.
- Experimental design: 2 × 2 between-subjects design crossing:
- Perpetrator type: Human (“Tod Smith”) vs. AI (“TodSMith”)
- Bias explicitness: Blatant (explicit racial slurs) vs. Subtle (neutral but unfair justification)
- Vignettes depicted biased hiring decisions across professional contexts.
Stage 2: Measures
- Dependent variables:
- Affect, operationalized using the Profile of Mood States (POMS)
- Perceived racism in the vignette scenario
- Blame attribution across three levels: perpetrator, AI trainer, and society
- AI familiarity (measured only in the AI condition)
Stage 3: Analysis
- Employed ANOVA to test main and interaction effects of agent type, bias explicitness, and perceiver race.
Results
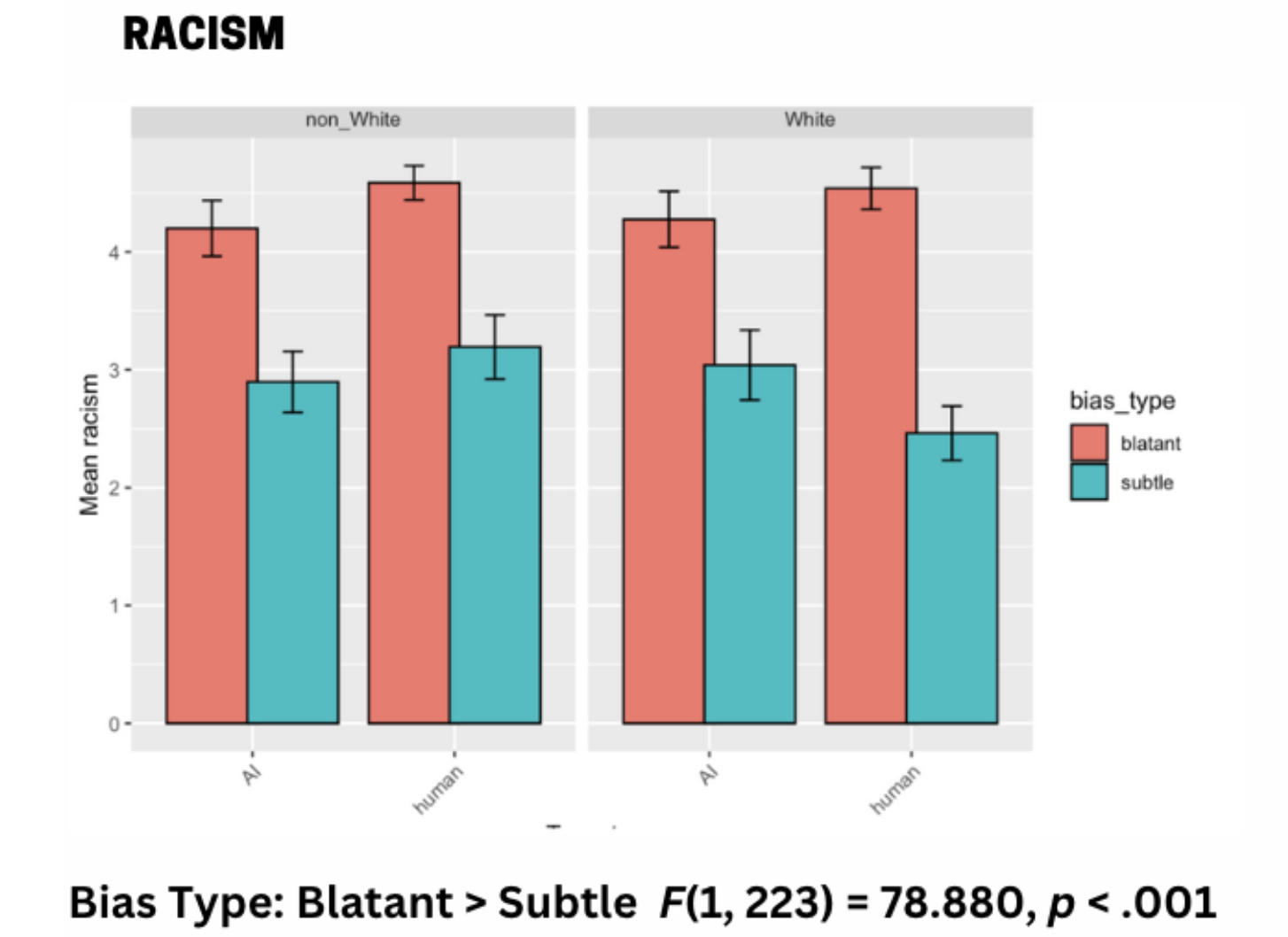
- Blatant bias evoked stronger emotional upset and higher racism ratings than subtle bias (p < .001).
- Humans were blamed more than AI for biased actions, especially when bias was blatant (p < .01).
- AI trainers were blamed more when bias originated from an AI agent (p < .001).
- No significant interaction of perceiver race on upset or blame attribution.
- Non-White participants reported greater resentment than White participants (p < .01).



Reflection
This study demonstrates that people differentiate between moral agency and technical causation—seeing AI as less blameworthy but still linked to human responsibility. The findings highlight how public understanding of AI bias intertwines with moral psychology, revealing both empathy and detachment toward algorithmic agents.
Future directions include expanding to cross-cultural samples, manipulating intentionality cues (e.g., self-learning AI vs. human-programmed systems), and examining how outcome severity moderates moral evaluation.
Programming & Tools Summary
| Stage | Programming Language/Software | Key Libraries / Methods |
|---|---|---|
| Data Collection | Qualtrics | |
| Data Cleaning | Python | Pandas, NumPy, regex |
| Statistical Analysis | R | Base R, lm4 |
| Visualization | R | ggplot2 |